
Introduction
Real-time analytics is becoming increasingly essential across industries, enabling businesses to derive insights and respond to events as they occur. Apache Kafka, an open-source distributed event-streaming platform, has emerged as a trend-setting technology for building real-time analytics systems. Its ability to handle high-throughput data streams and ensure low latency makes it a cornerstone for organisations aiming to modernise their analytics infrastructure. Learning how to leverage these capabilities effectively is often a key focus of a Data Science Course, as it equips professionals with practical skills for handling real-time data.
This article explores the core components, architecture, and best practices for building real-time analytics systems using Apache Kafka.
Understanding Apache Kafka
Apache Kafka is designed to facilitate real-time data processing by providing a reliable and scalable platform for publishing, storing, and consuming event streams. Basically, Kafka operates as a distributed log system, where events (or messages) are stored in topics and made available to consumers in real-time.
Key features of Kafka include:
- Scalability: Kafka can handle millions of events per second, making it suitable for large-scale applications.
- Fault Tolerance: Its distributed architecture ensures data availability even in the case of server failures.
- Durability: Kafka persists messages in the disk, providing robust recovery mechanisms.
- Decoupling Producers and Consumers: Kafka allows producers to send data and consumers to process it independently, ensuring flexibility in system design.
These features make Kafka an ideal choice for real-time analytics systems, where low latency and high availability are crucial. Understanding these principles is often part of the curriculum of a well-rounded data course. For instance, a Data Science Course in Mumbai will include extensive coverage on these topics, which form the foundation of modern data engineering practices.
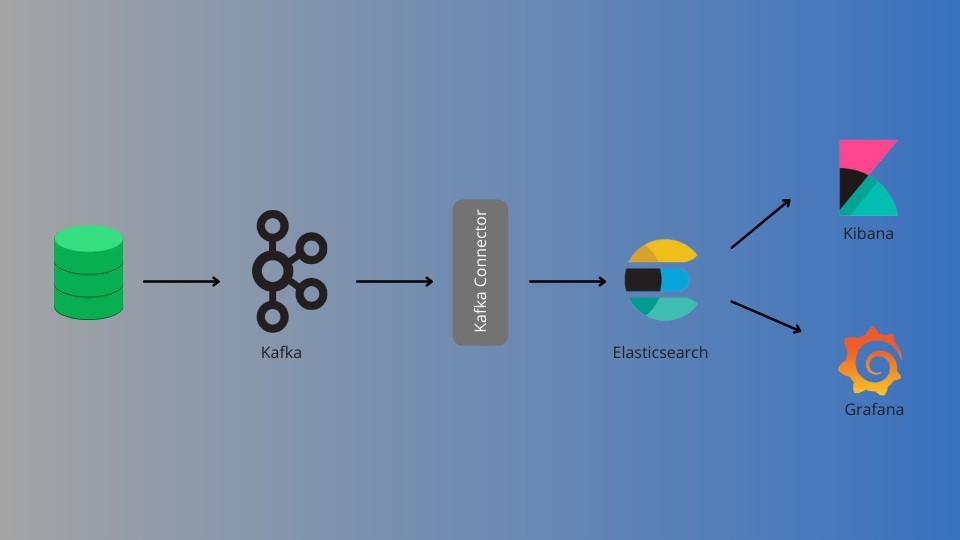
Components of a Kafka-Based Real-Time Analytics System
Producers: Applications or systems that send event data to Kafka topics. Examples include IoT devices, transaction systems, and web applications.
- Kafka Topics: Logical partitions where events are stored. Each topic can have multiple partitions, allowing parallelism and scalability.
- Brokers: Kafka servers that store and distribute topic data. Brokers work together in a cluster to manage data efficiently.
- Consumers: Applications or services that read events from Kafka topics. These can be analytics engines, dashboards, or machine learning models.
- Stream Processing Layer: Tools such as Kafka Streams, Apache Flink, or Apache Spark can process data in real-time, enabling complex transformations and analytics.
- Data Storage and Visualisation: Processed data can be stored in databases like Apache Cassandra or Elasticsearch and visualised using tools like Grafana or Kibana.
Practical exercises involving these components are often included in a Data Science Course, enabling participants to gain hands-on experience in building and managing Kafka pipelines.
Key Steps in Building Real-Time Analytics with Kafka
Following are the key steps involved in building real-time analytics with Kafka.
Defining Use Cases and Requirements
Before implementing a Kafka-based system, clearly define the analytics use cases. For instance:
- Customer Behaviour Tracking: Real-time analysis of user interactions on an e-commerce website.
- Fraud Detection: Monitoring financial transactions for anomalous patterns.
- IoT Data Processing: Aggregating and analysing sensor data from connected devices.
Define the data sources, throughput requirements, and desired latency to ensure the system is designed for optimal performance.
Setting Up Kafka
- Deploying Kafka: Install and configure a Kafka cluster, ensuring sufficient resources for the expected data volume.
- Topic Configuration: Create topics with appropriate partitioning and replication factors to balance performance and fault tolerance.
Data Ingestion
- Integrate producers to send data into Kafka topics. For example, use Kafka Connect to ingest data from relational databases, APIs, or message queues.
- Ensure data is serialised into formats like Avro, JSON, or Protobuf for compatibility with downstream systems.
Stream Processing
Use Kafka Streams or an external framework like Apache Flink to perform real-time data transformations and aggregations. Examples include:
- Calculating rolling averages or time-based aggregates.
- Filtering events based on specific conditions.
- Enriching data with additional context from external sources.
Storage and Querying
- Store processed data in real-time databases like Druid, Cassandra, or MongoDB for fast querying.
- Use time-series databases for scenarios like IoT analytics or application monitoring.
Visualisation and Reporting
- Integrate visualisation tools like Grafana, Tableau, or Kibana to build interactive dashboards.
- Configure alerts and notifications for critical events detected in real-time.
Best Practices for Kafka-Based Analytics Systems
Here are some best practice tips recommended in building real-time analytics with Kafka-based analytics systems.
Optimise Topic Design
- Partition topics effectively to distribute load across brokers and improve throughput.
- Use meaningful topic naming conventions to simplify management.
Ensure Data Quality
- Validate data at the producer level to avoid ingesting corrupt or incomplete events.
- Implement schemas using tools like Apache Avro or Protobuf to enforce data consistency.
Monitor and Scale
- Use Kafka monitoring tools like Confluent Control Center or open-source options like Prometheus and Grafana to track cluster performance.
- Scale brokers and partitions dynamically to handle increased traffic.
Secure the Kafka Cluster
- Implement authentication (for example, SASL) and encryption (for example, SSL/TLS) to protect data in transit.
- Use access control mechanisms to restrict unauthorised access to topics.
Leverage Stream Processing Libraries
- Choose a stream processing framework based on the complexity of analytics. Kafka Streams is ideal for lightweight processing, while Apache Flink suits advanced use cases.
Courses like a Data Science Course often emphasise these best practices, ensuring that learners can design systems that are not only functional but also efficient and secure.
Example Use Case: E-Commerce Analytics
Consider an e-commerce platform that wants to track customer behaviour in real-time to optimise the user experience and increase sales.
Data Sources
- Clickstream data from the website.
- Transaction data from the payment gateway.
- Inventory updates from the warehouse.
Kafka Setup
- Producers send data to topics like user_interactions, transactions, and inventory_updates.
- Stream processing identifies high-traffic products and correlates them with inventory levels.
Real-Time Insights
- Dashboards display popular products and real-time inventory levels.
- Alerts notify the operations team when stock levels drop below a threshold.
Outcome
- Faster decision-making to restock popular items.
- Improved user experience through personalised recommendations.
Such hands-on scenarios are often included in a career-oriented data course, such as a Data Science Course in Mumbai tailored for working professionals. These courses provide learners with practical experience in implementing real-time analytics systems.
Challenges and Future Directions
Following are some common challenges that must be addressed in using Kafka for real-time analytics.
- Handling Data Spikes: Real-time systems must manage sudden spikes in traffic without compromising performance. Autoscaling Kafka clusters and stream processing frameworks can address this challenge.
- Ensuring Data Reliability: Guaranteeing exactly once processing can be complex but is essential for financial or mission-critical applications. Kafka’s transactional APIs help achieve this goal.
- Integration with AI and ML: Real-time analytics systems can be enhanced by integrating machine learning models for predictive insights. For instance, combining Kafka with ML platforms enables use cases like dynamic pricing or anomaly detection.
Acquiring skills in these advanced integrations helps professionals prepare for the future of real-time data processing.
Conclusion
Apache Kafka provides a sound foundation for building real-time analytics systems that deliver timely insights and drive business outcomes. By carefully designing the architecture, leveraging advanced stream processing, and adhering to best practices, organisations can unlock the full potential of real-time analytics.
Enrolling in a Data Science Course not only helps individuals understand these concepts but also equips them with the technical expertise to design, implement, and maintain real-time analytics systems effectively. As industries continue to embrace data-driven decision-making, mastering these skills will remain a valuable asset for professionals.
Business Name: ExcelR- Data Science, Data Analytics, Business Analyst Course Training Mumbai
Address: Unit no. 302, 03rd Floor, Ashok Premises, Old Nagardas Rd, Nicolas Wadi Rd, Mogra Village, Gundavali Gaothan, Andheri E, Mumbai, Maharashtra 400069, Phone: 09108238354, Email: enquiry@excelr.com.
